Paper
Architecture
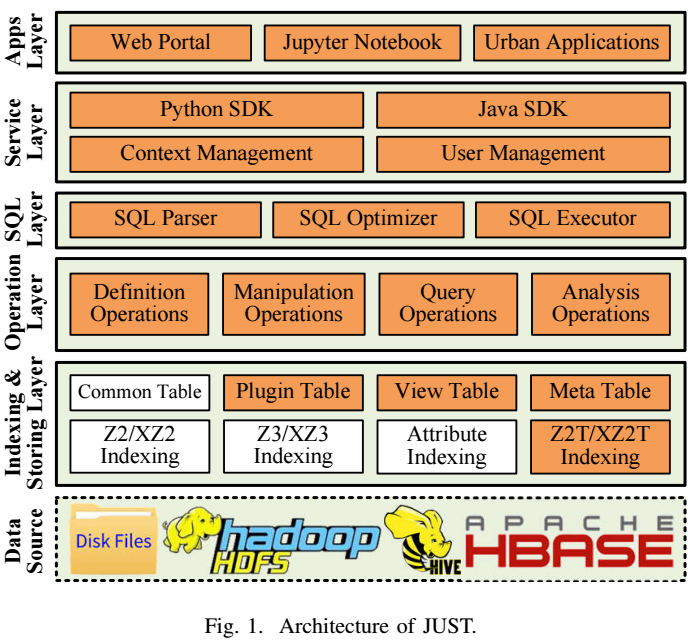
Key Features
(1) Scalability
(2) Efficiency
(3) Update-enabled
(4) Easy of Use
(5) Multi Execute Engines Supported
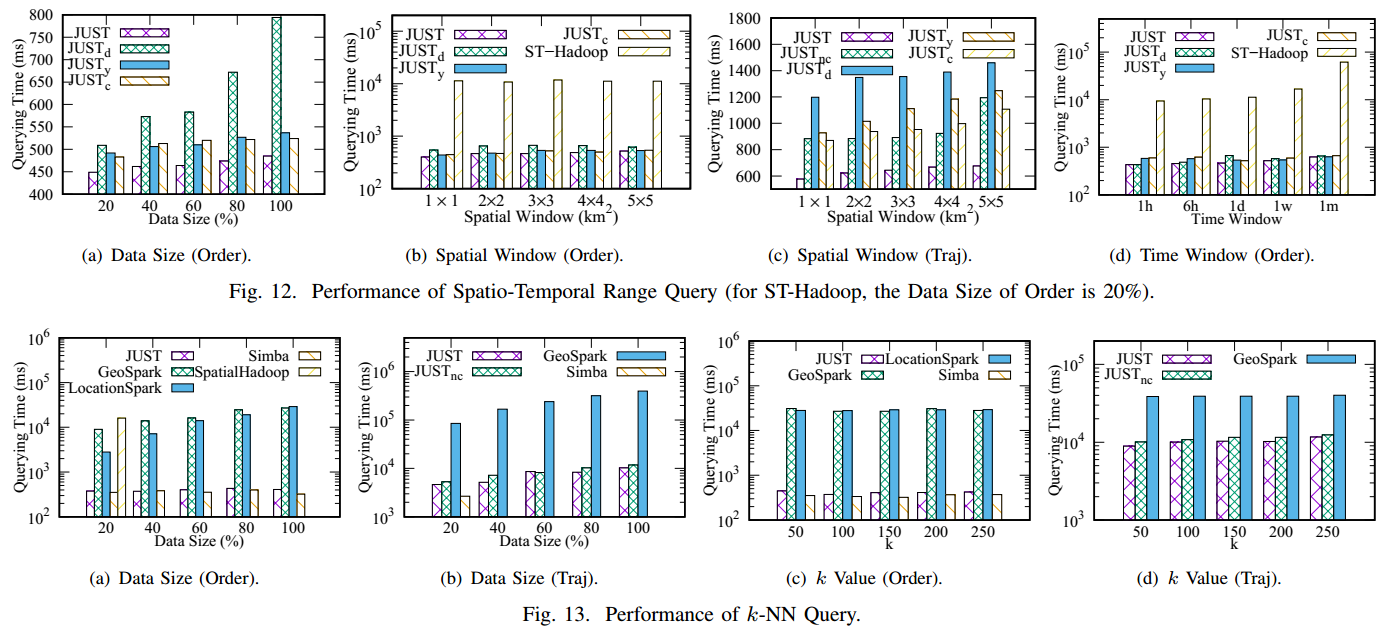
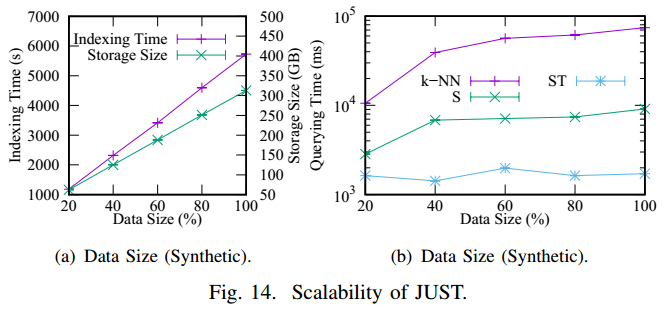
Experiments
Data Settings
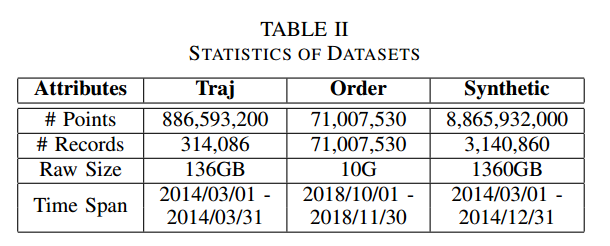

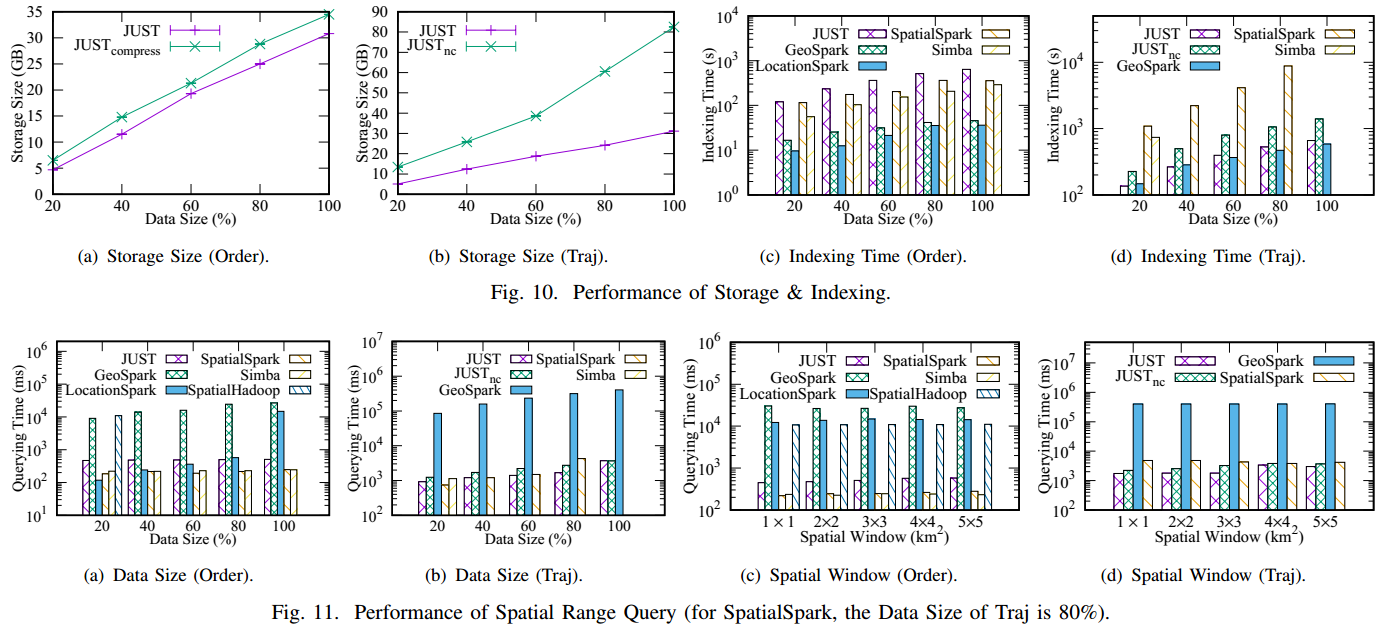
Results
Experimental Code
Applications
-

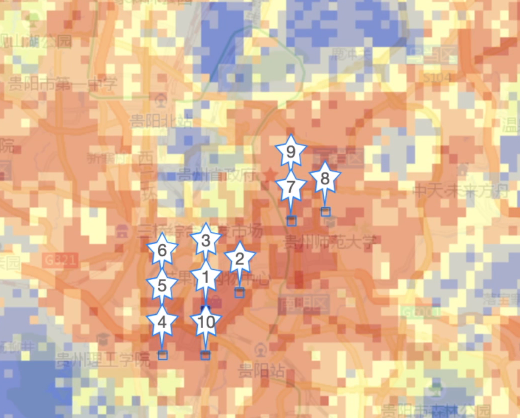
Urban Block Indicator System
This system is built to give a general overview of any urban area (a.k.a address portrait). It first partitions the spatial space into about 150m × 150m grids, then calculate multiple indicators of each grid, e.g., purchasing power, air quality, traffic flow, and etc, using multiple spatio-temporal data sources. The indicators of fine-grained urban areas are very helpful for billboard placement, location selection, and urban planning. Users can search the indicators of any area using a spatio-temporal range query based on JUST.
-
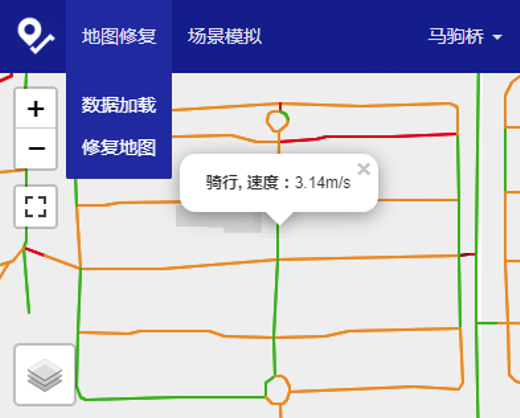
Map Recovery System
This system utilizes the trajectories of couriers in JD Logistics to recover the road networks of living areas, which could be missing in commercial maps. A complete map is essential for path planning and package dispatching. The GPS logs of over 60,000 couriers are loaded into JUST in batches each day. With the help of JUST to manage and process trajectories, the map recovery system can repair the road networks in living areas, and infer the speed and traffic mode (e.g., riding or walking) of each road segment with much fewer efforts.
-
Unicom Service Center Location Selection
Based on the Urban Block Indicator System, this system can help China Unicom to answer the following questions: 1) Where the new stores should be opened to attract target customers at most? 2) How to make bussiness strategies according to the current customers and surrounding environmental situations? This system is based on multiple data sources (e.g., cellular signaling data, demographic data, JD purchasing order data, road networks, and POIs), and adopts multi-source data fusion technology and cross-domain learning techniques.
-
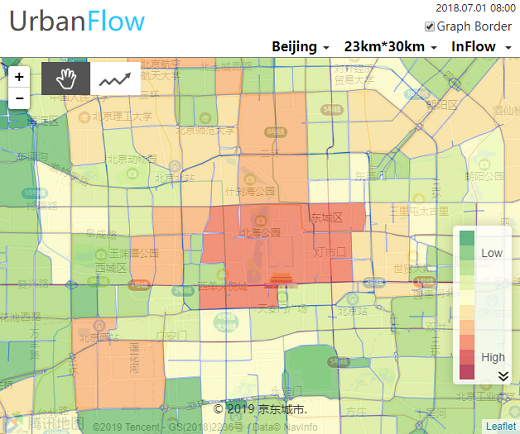
Urban Crowd Flow Prediction
Forecasting the flow of crowds is of great importance to traffic management and public safety, and very challenging as it is affected by many complex factors, including spatial dependencies (nearby and distant), temporal dependencies (closeness, period, trend), and external conditions (e.g. weather and events). This system predicts the city-wide crowd flow with the help of JUST. In this case, JUST provides efficient real-time or historical crowd flow calculation, and spatio-temporal data processing. The demo system is shown in http://101.124.0.58/urbanflow_graph/.
-
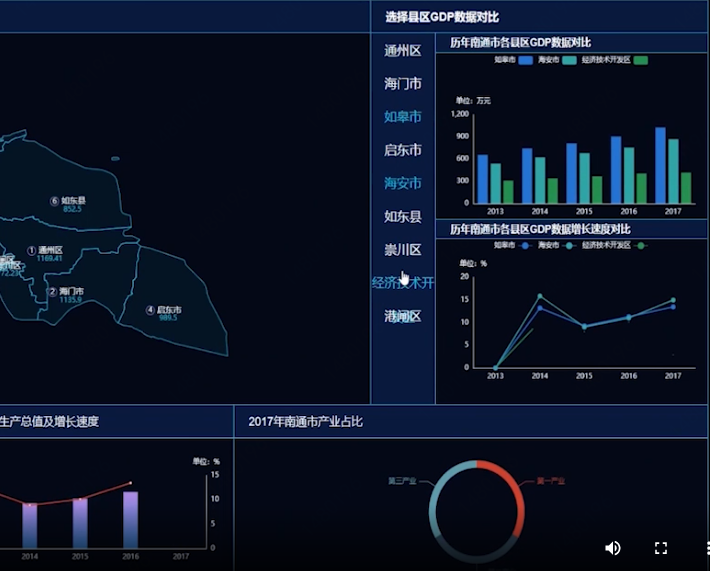
JD Logistics Real Estate
From the spatio-temporal perspective, we display the macroeconomic, microeconomic, industrial distribution, transportation facilities, real estate layout, natural disasters, enterprise chains and other data in a multi-dimensional combination, and build a complete city (grid) potential rating model based on six categories of indicators: transportation, economy, geographic characteristics, users, enterprises and commercial activities. The potential scoring model helps decision makers grasp the potential of urban property development from a macro perspective and assist in site selection decisions.
Quick Start
Login
User Name and Password, then click the button 登录, as shown in the following picture.
Table Panel, View Panel, JustQL Panel, and Result Panel.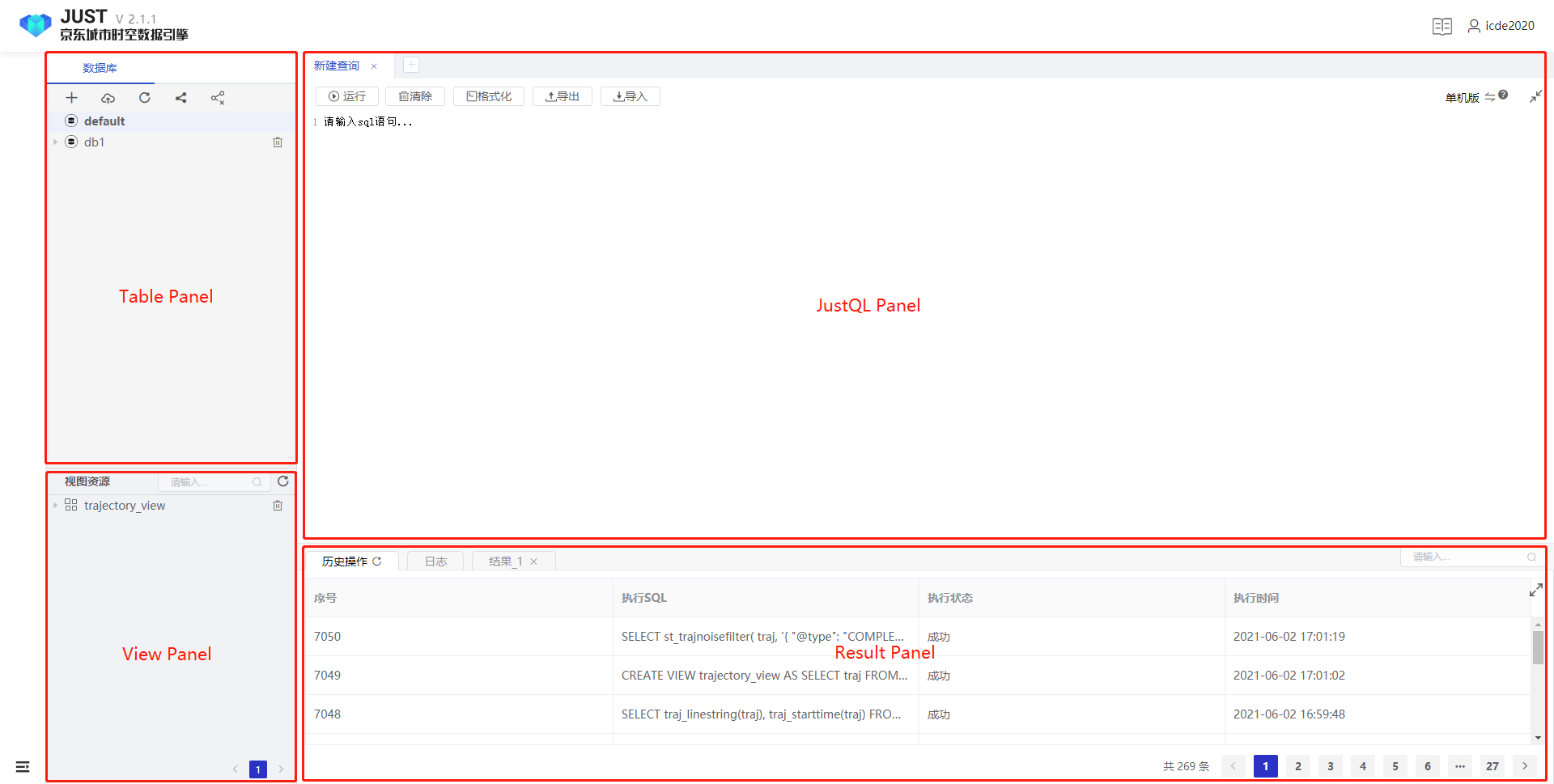
An Example of the Order Data (Common Table, Point-based Data)
CREATE TABLE order_table(
order_time Timestamp,
order_position Point,
attr1 integer,
attr2 long,
attr3 long,
attr4 integer,
attr5 string,
attr6 integer,
attr7 integer,
attr8 integer,
attr9 string,
attr10 string,
attr11 string,
attr12 double,
attr13 integer,
attr14 integer,
attr15 integer,
attr16 integer,
attr17 integer
) WITH (
"geomesa.indices.enabled" = "z2,z2t",
"geomesa.z3.interval" = "day",
"geomesa.xz.precision" = "16"
);
LOAD hive :just_tutorial.order_table to JUST :order_table (
order_time to_timestampInMS(time),
order_position st_makePoint(lng, lat),
attr1 attr1,
attr2 attr2,
attr3 attr3,
attr4 attr4,
attr5 attr5,
attr6 attr6,
attr7 attr7,
attr8 attr8,
attr9 attr9,
attr10 attr10,
attr11 attr11,
attr12 attr12,
attr13 attr13,
attr14 attr14,
attr15 attr15,
attr16 attr16,
attr17 attr17
);
SELECT
order_time,
order_position,
attr12
FROM
order_table
WHERE
st_within(
order_position,
st_makebbox(116, 39, 116.5, 39.5)
)

SELECT
order_time,
order_position,
attr12
FROM
order_table
WHERE
st_within(
order_position,
st_makebbox(116, 39, 116.5, 39.5)
)
AND order_time >= '2018-10-01 00:00:00'
AND order_time <= '2018-11-01 00:00:00'
SELECT
*
FROM
order_table
WHERE
st_knn(
order_position,
'POINT(115.71 39.57)',
'common',
2
)
CREATE VIEW order_view AS
SELECT
*
FROM
order_table
WHERE
attr12 > 3
AND st_within(
order_position,
st_makebbox(116, 39, 116.5, 39.5)
)
LIMIT
200
STORE VIEW order_view TO TABLE order_table_small
DBSCAN method:
SELECT
st_dbscan('order_position', t1, 1, 1)
FROM
(
SELECT
collect_list(struct(*)) AS t1
FROM
order_table_small
)
minPts and radius respectively, representing there are at least minPts points within distance radius meters of a core point.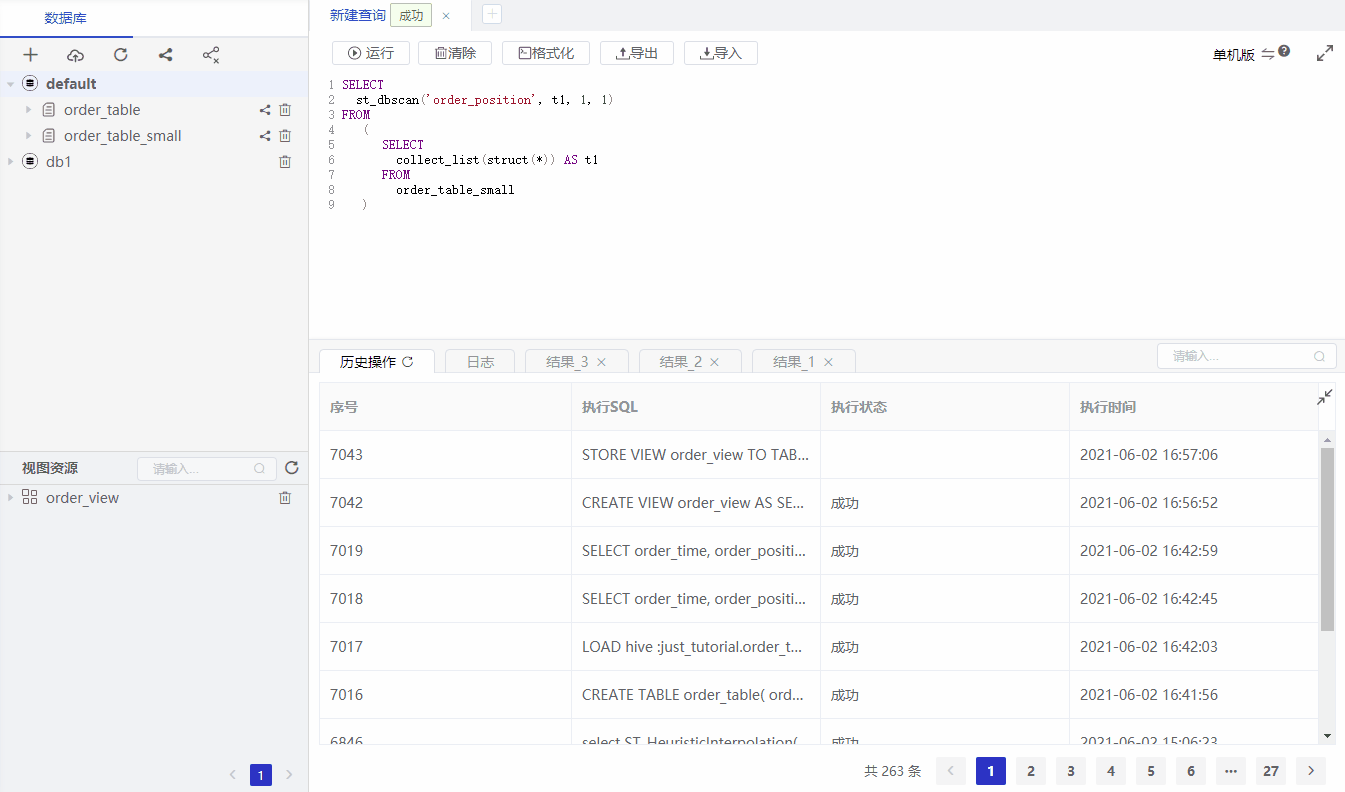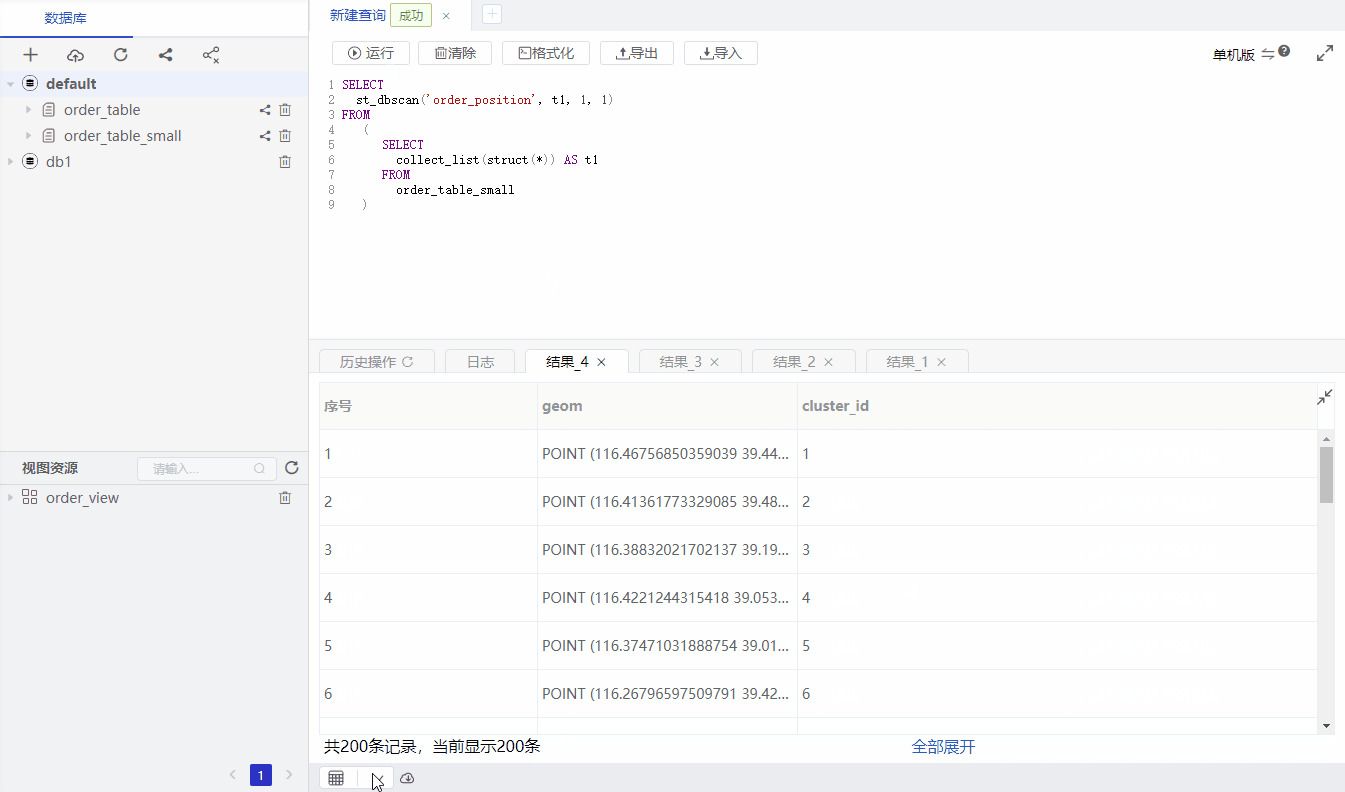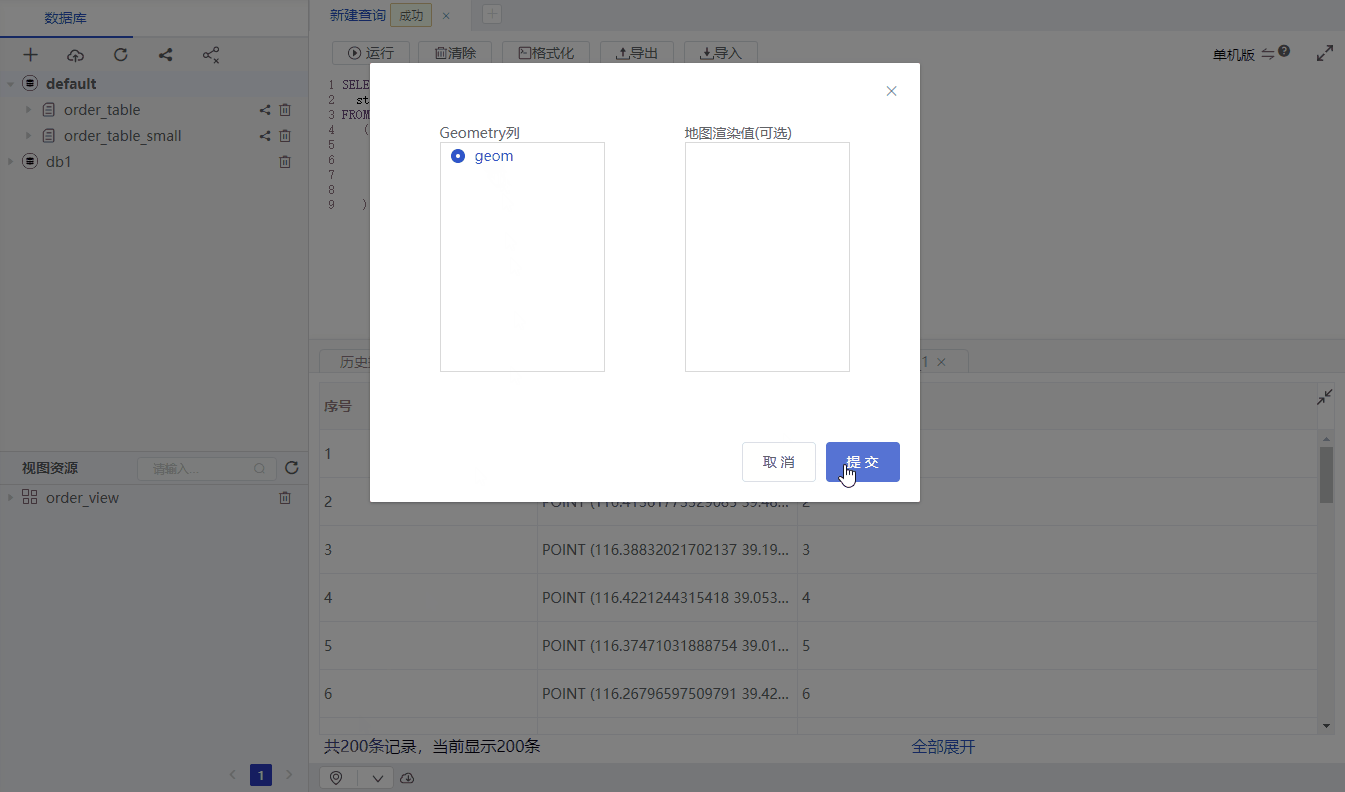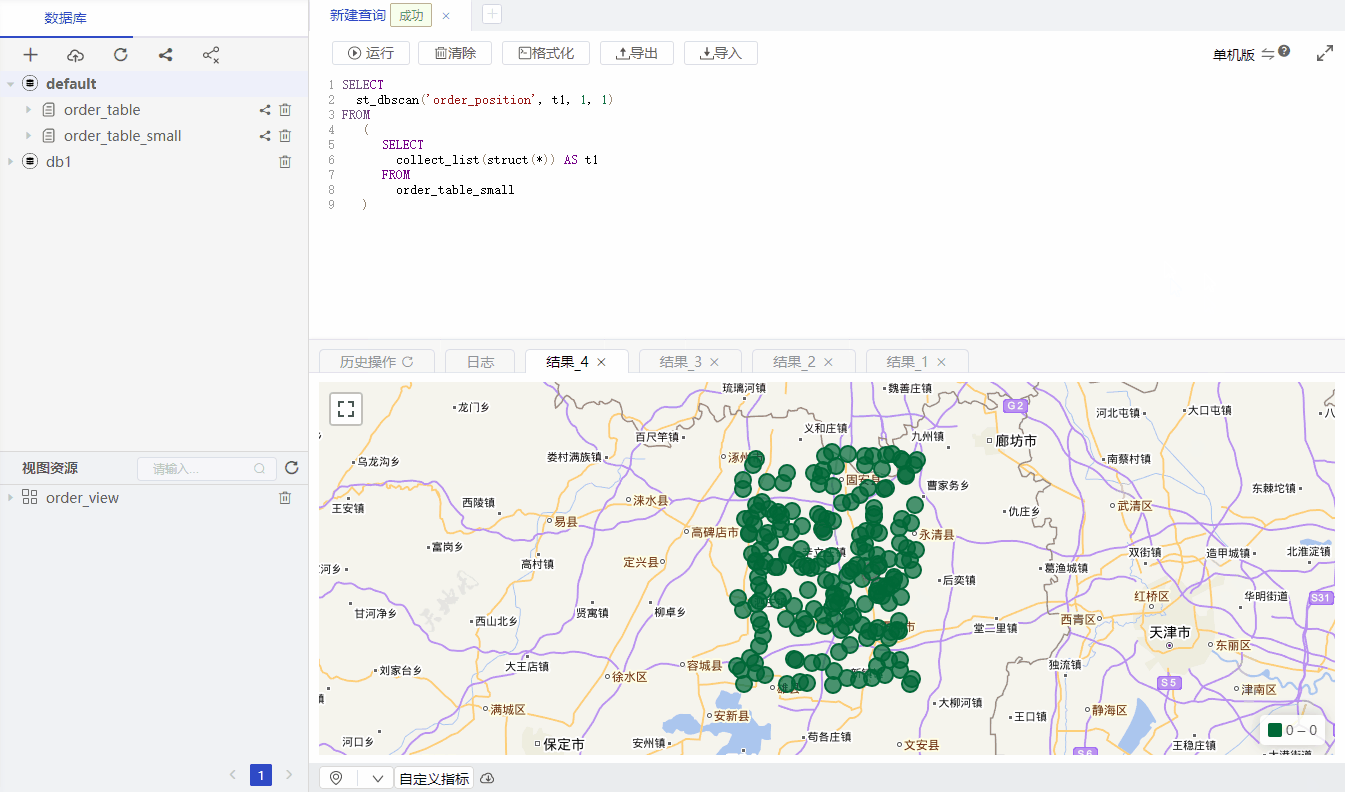
DROP VIEW order_view
DROP TABLE order_table
DROP TABLE order_table_small
An Example of the Traj Data
CREATE TABLE trajectory_table (traj Trajectory)
LOAD hdfs:'/just_tutorial/trajectory_data' to JUST:trajectory_table (
traj.oid 0,
traj.time to_timestamp(3),
traj.point st_makePoint(1,2)
);
SELECT
traj_linestring(traj), traj_starttime(traj)
FROM
trajectory_table
WHERE
st_within(
traj_linestring(traj),
st_makebbox(113.1, 23.2, 113.5, 23.6)
)

SELECT
*
FROM
trajectory_table
WHERE
st_within(
traj_linestring(traj),
st_makebbox(113.1, 23.2, 113.5, 23.6)
)
AND traj_starttime(traj) > '2014-03-01 00:00:00'
AND traj_starttime(traj) < '2014-03-15 00:00:00'
SELECT
*
FROM
trajectory_table
WHERE
st_knn(
traj,
'POINT(115.71 39.57)',
'common',
2
)
CREATE VIEW trajectory_view AS
SELECT
traj
FROM
trajectory_table
WHERE
st_within(
traj_linestring(traj),
st_makebbox(113.1, 23.2, 113.5, 23.6)
)
SELECT
st_trajnoisefilter(
traj,
'{ "filterType": "COMPLEX_FILTER",
"maxSpeedMeterPerSecond": 100.0,
"segmenterParams": { "maxTimeIntervalInMinute": 60,
"maxStayDistInMeter": 100,
"minStayTimeInSecond": 100,
"minTrajLengthInKM": 1,
"segmenterType": "ST_DENSITY_SEGMENTER"}}'
)
FROM
trajectory_view
st_trajNoiseFilter is to config which filter method is used. If omited, we will use the default method.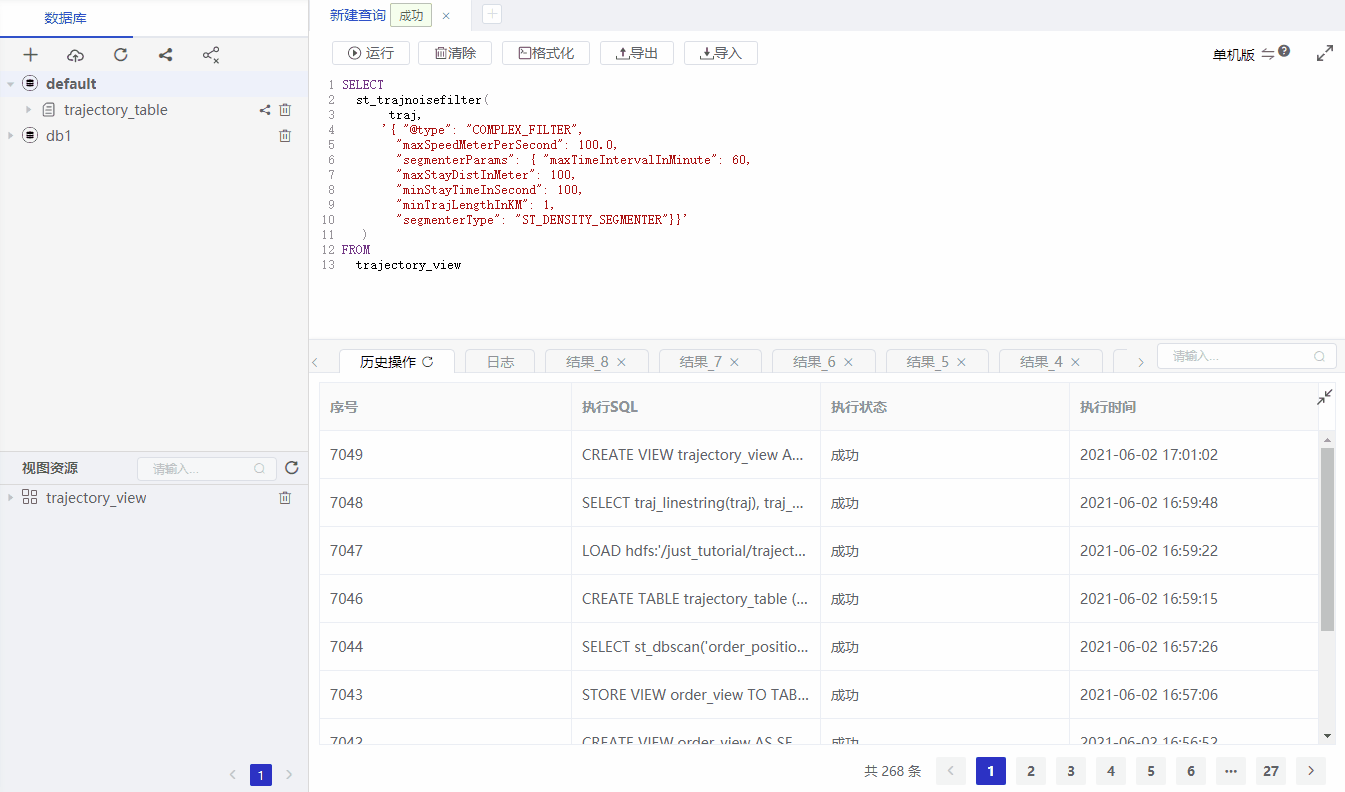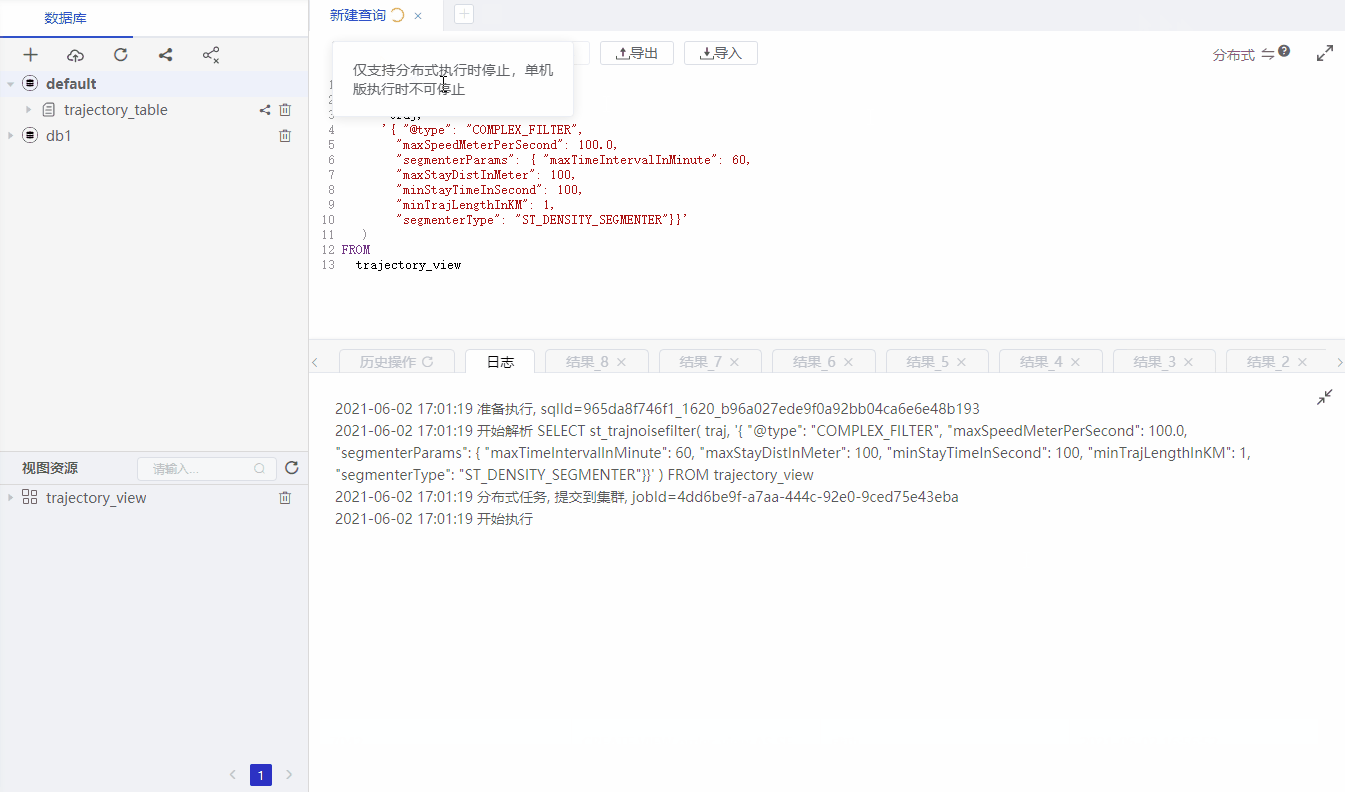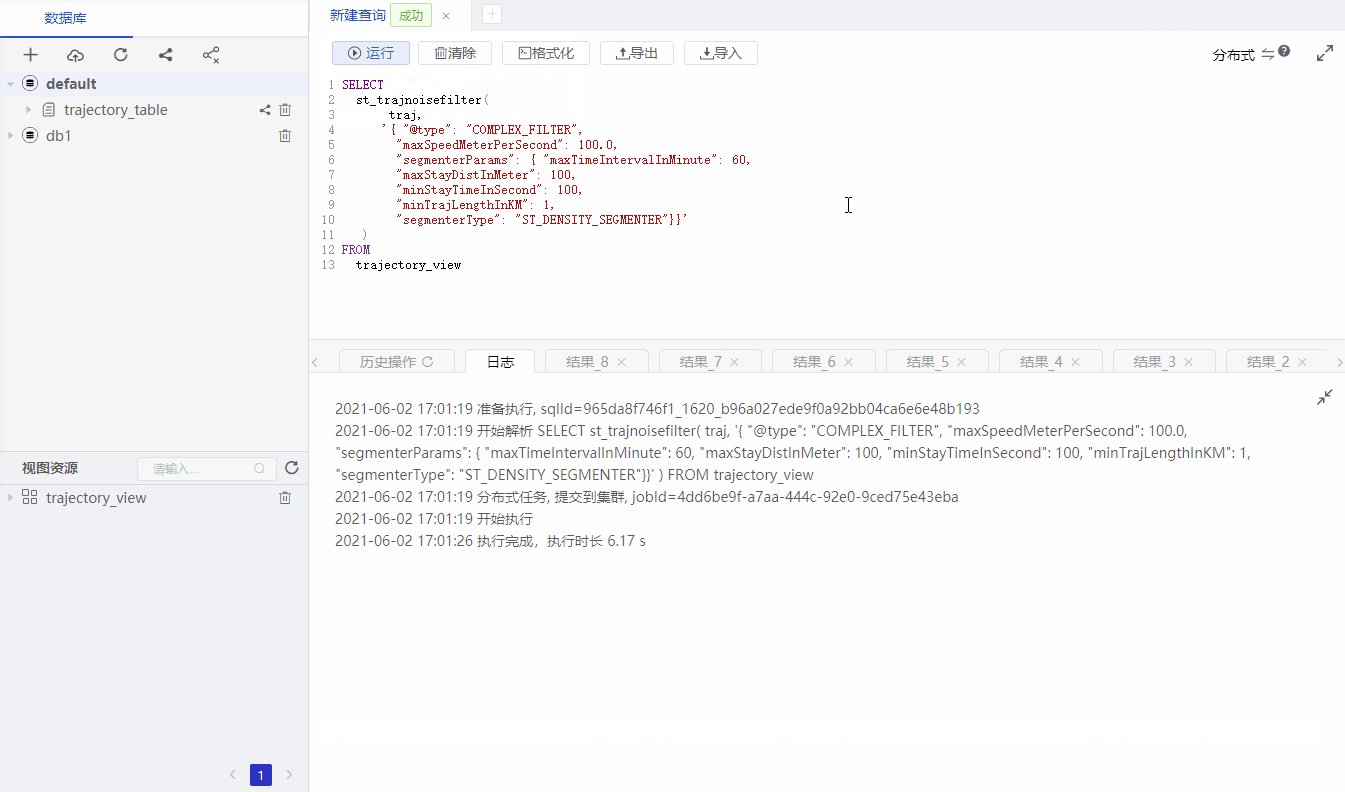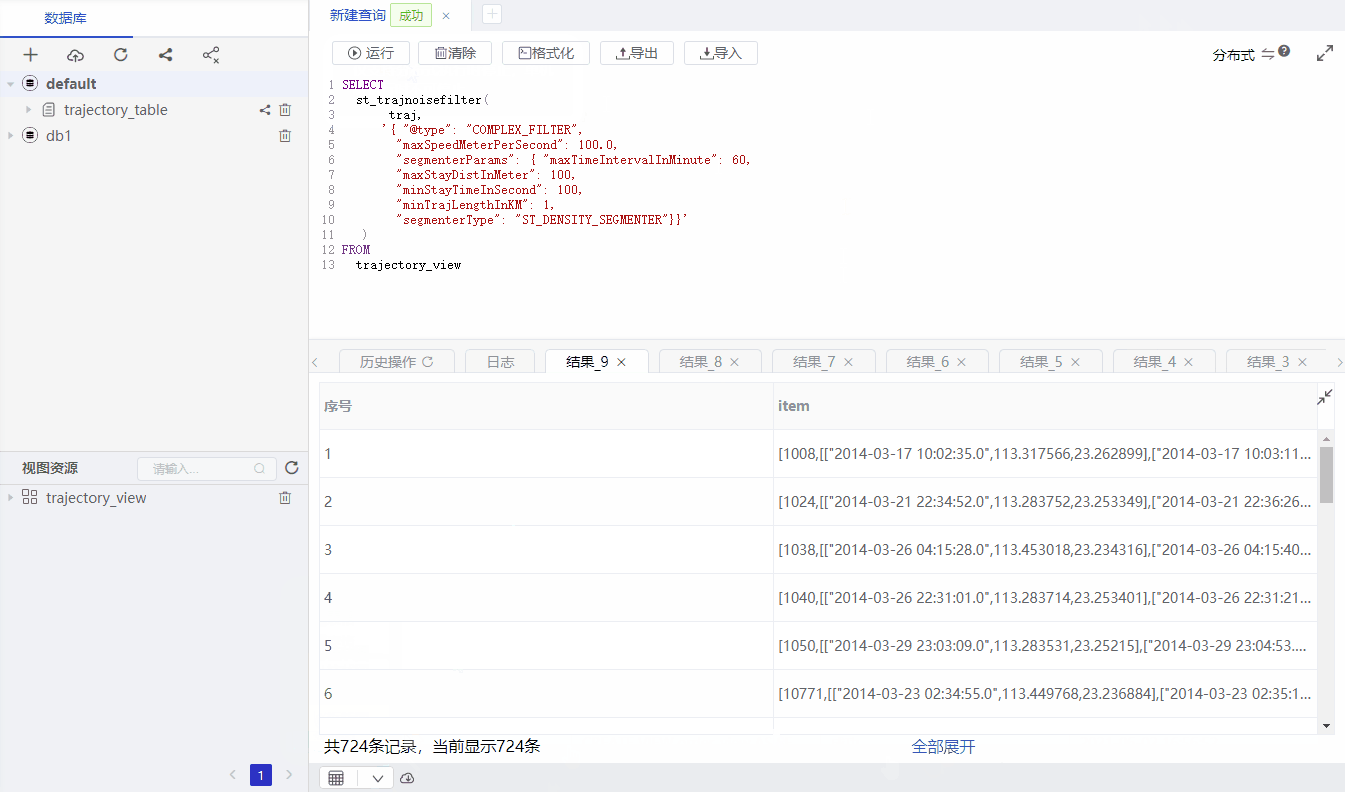
SELECT
st_trajsegmentation(
traj,
'{ "maxTimeIntervalInMinute": 10,
"maxStayDistInMeter": 100,
"minStayTimeInSecond": 100,
"minTrajLengthInKM": 1,
"segmenterType": "HYBRID_SEGMENTER"}'
)
FROM
trajectory_view
st_trajSegmentation is to config which segmentation method is used. If omited, we will use the default method.
SELECT
st_trajStayPoint(
traj,
'{ "maxStayDistInMeter": 10,
"minStayTimeInSecond": 60,
"stayPointType": "CLASSIC_DETECTOR"}'
)
FROM
trajectory_view
st_trajStayPoint is to config which stay point detection method is used. If omited, we will use the default method.
CREATE VIEW stay_point_view AS
SELECT
st_trajStayPoint(
traj,
'{ "maxStayDistInMeter": 10,
"minStayTimeInSecond": 60,
"stayPointType": "CLASSIC_DETECTOR"}'
)
FROM
trajectory_view
STORE VIEW stay_point_view TO TABLE stay_point_table
DROP VIEW trajectory_view
DROP VIEW stay_point_view
DROP TABLE trajectory_table
DROP TABLE stay_point_table
An Example of the Road Network Data
CREATE TABLE guiyang_rn (road roadSegment)
CREATE TABLE guiyang_traj_table (traj Trajectory)
LOAD hdfs: '/just_test_lhy/data/roadnetwork/guiyang_rn.csv' TO just: guiyang_rn(
road.oid oid,
road.direction direction,
road.speed_limit speed_limit,
road.level level,
road.geom st_linefromtext(geom)
) WITH ("just.separator" = "|", "just.header" = "true")
LOAD hdfs :'/just_tutorial/guiyang_traj.csv' TO JUST :guiyang_traj_table (
traj.oid oid,
traj.time to_timestamp(time),
traj.point st_makePoint(lng, lat)
) WITH ("just.separator" = "|", "just.header" = "true")
SELECT
*
FROM
guiyang_rn
WHERE
st_within(
roadsegment_linestring(road),
st_makebbox(106.674686,26.635553,106.712055,26.667067)
)
SELECT
st_trajLmmMapMatchToProjection(t1.traj, t2.t)
FROM
guiyang_traj_table t1,
(
SELECT
st_makeRoadNetwork(collect_list(road)) AS t
FROM
guiyang_rn
) AS t2
DROP TABLE guiyang_rn
DROP TABLE guiyang_traj_table